Why Kubernetes for microservices architecture? Why orchestration is essential
Intro
Lets say you have decided to implement a microservices architecture.
How do I manage containers? What does it involve? What is my team’s commitment?
There is many things to consider for microservices, but here is what I can say. If you start learning about it, you will soon realise that the study of microservices, containers and Kubernetes itself could be days if not months worth of learning. If you don’t have a clear direction then you will quickly lose yourself in the sea of information.
Today, I’ll summarise Just Enough information to get a glimpse of what is involved with containers and about automation. This blog is written especially for those that currently use traditional IT like on-premise, or cloud on a non-containerised environment like virtual servers.
I do have an end goal in my explanation, and that is to show why ‘managed Kubernetes’ is better than Kubernetes., and why Kubernetes is better than just managing containers (To the level it is almost crucial due to more efficient operations).
FUN FACT: Previously I have wrote another blog on the purposes and implications of considering microservices, check that one out too!
Before I start, quick definition of containers/microservices. These explanations might not click at the moment, but I will keep referring back to it so that we can see the importance of these nature:
Quick definition of containers / microservices
A) The Pet vs Cattle analogy: In a monolith application, services are nurtured like precious pets but when it fails everything falls down. In reverse, machines in microservices are expected to fail, and when it does, it can easily be replaced using built-in automation.
B) Containers are loosely-coupled: It is decentralised, or detached from each other and communicates with each other.
C) Microservices work on a distributed computing environment: Due to it’s decentralised nature it can run anywhere and will be designed to run everywhere.
Question 1: Can your operations team handle workloads for managing containers manually?
Well what’s involved in managing containers? Lets start with Just Enough insight for containers! (and images!) using Docker as an example.
So first, what problems do containers solve?
Definition A: Pet vs Cattle analogy implies Scaling-up or Scaling-out. The problem with traditional monolith design servers is that they grow bigger and bigger when further components are added (scale-up). This is concerning when that one heavy server or application goes down, it causes massive issues but it is also very difficult to roll out updates too since it’s hard to rebuild it often. Imagine the panic when your nurtured home pet gets seriously sick.
Containers on the other hand are light-weight and different components are all kept separate. Each component is replaceable and they are detached from each other but communicates with each other well. Containers scale-out by increasing the number of containers instead of adding more and more onto existing servers/applications. This is like a cattle being replaced in the ‘expect to fail’ mentality, it does not cause as much confusion and can easily be replaced. Several benefits of the cattle approach include high availability, easier scaling and integrates well with CI/CD.
So with containers, it is important that when one container fails, another one can step in very quickly. How do we achieve that? Using blueprints!
When I say blueprints, this is just a metaphor and it is not a technical term called ‘blueprints’. You may come across various types of blueprints too, because this is key to microservices design where you have a form of master sheet, then you can quickly produce identical copies from it.
With containers, we use a type of blueprint called images. I’m sure images are nothing new if you have already used virtual servers, created an image from it and did a reload of that image into the server.
A container image is an immutable (unchangeable) file with everything required to run an application in a container. In fact, you cannot start a container without images.
For this blog I will explain containers using Docker. Docker is an opensource container engine, and it is a full suite of technology that allows the container lifecycle management. I say it is a full suite because there are other container runtimes like CRI-O which is used to run containers, but it will need to be integrated with other components to work. Docker too is not the only option for containers (Kubernetes also recently stopped supporting Docker for default use, but that’s a different story!).
In other words, just by having Docker you can do pretty much everything to keep the container running.
The basic flow of running a container is like below:
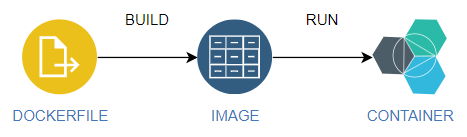
- You first need to use what’s called a Dockerfile, which is a text file that you configure in order to build the image you want.
- An image is created, and you would typically store this in a container registry
- You will start a container by running it from an existing image
How do you do all these? Typically in Docker, you will use Docker commands from CLI interface to execute all these:
Docker command reference
Great, so the operations team will use commands like ‘docker start’ to manage the lifecylcle of containers, run applications like web apps and databases on a container, have a couple of them and quickly replace them when they have issues right?
Well yes, and there is networking and setting up the interdependencies and more. Managing all that manually is a lot of work and the operational expense is high. Why not automate it?
There comes Container orchestration tools. Docker swarm is one option, but a more popular option is Kubernetes since you can do much more.
Question 2: Can your operations team handle workloads for non-managed Kubernetes?
Kubernetes as the orchestrator can be said to be the framework to run distributed systems resiliently. It takes care of your scaling requirements, failover, deployment patterns and more. It is like a babysitter for the containers.
In Kubernetes, you define the ideal state, then the orchestrator will automate processes to achieve that ideal state. Say if a node fails, then there is built-in monitoring that quickly shows that the ideal state is not reached anymore, then Kubernetes will spin up another node and get it back to the ideal state again. These configurations are written in YAML files. Yes, there is literally a parameter you can set which goes: replicas: 2 Then if the replica drops to 1 due to failure, it will self-heal.
Before we start explaining this, lets start by looking at the 3 core components of Infrastructure: Compute, Network and Storage and see how Kubernetes implements these.
Explanation is just enough to get an idea and you may wish to learn more separately to get a deeper understanding.
1. Compute
Pods and deployments (and ReplicaSets)
In Kubernetes, a pod is the smallest unit and we usually have one application (container) per pod. (Can have more but for the simplicity generally we have one). However generally we don’t control neither the pod or the container itself. This is because in Kubernetes, these are abstracted away.
The pod abstracts away the container, another system call ReplicaSet manages pods, and Deployments manage ReplicaSets.
So for the operations team, what we really need to be concerned of is the Deployments, and the rest is all abstracted away and automated within the orchestration system.
A deployment runs multiple replicas of your application and automatically replaces any instances that fail or become unresponsive. A Deployment is the configuration I mentioned earlier, using YAML files you can set the ideal state and set various configurations and let Kubernetes handle the pods, the containers and everything else below the stack.
Another question you may have is, where does Kubernetes place these applications/containers?
Worker nodes and Master nodes
In traditional computing you will put application on servers. In Kubernetes we use nodes. A node is like one machine and it can have compute specs like 4 vCPUs and 16GB RAM. Typically when we say nodes, it refers to worker nodes.
There is also the master node that acts as the brain of the cluster. These master nodes are so intelligent that it can oversee all worker nodes to monitor the cluster health, check any state changes, understand what resources are available, and it will auto-allocate resources into worker nodes. When allocating resources, it will do so in a node that is least utilised (if 1 node is 30% used and rest is 60% used, then allocation goes to the former node).
Since Kubernetes will auto-allocate the resources into worker nodes for you, you wouldn’t have to worry about that part. However you are responsible of designing the compute resource availability such that there is enough worker nodes and master nodes for your application to function. Typically in production workloads you can have 2 master nodes or more, and much more worker nodes enough to scale. Auto-scaling feature is available too. For example, a command like below will set auto-scaling so if CPU percentage goes above 80%, then scale the pods starting from 4 and up to 10.
kubectl autoscale deployment
2. Network
Each pod will get it’s own IP address. What if pods die? Then new ones will be created and IP addresses will change, that will be an issue. That is why we have Services.
Service and Ingress controllers
Services will keep the IP statically available and will have it’s own lifecycle so if a pod dies, Services is still there and when a new pod comes into place the same IP can be allocated again and avoid disruption.
Services are used for internal networking within the Kubernetes cluster, and when exposing it, the Ingress Controller will be used. Ingress controllers provide load balancing, SSL termination and name-based virtual hosting, so generally any traffic flowing into the cluster will go through the ingress controller.
Ingress is a collection of routing rules that govern how external users access services that are running in a Kubernetes cluster. You can use Ingress to expose multiple app services to the public or to a private network by using a unique public or private route.
Namespaces
Namespaces are used to achieve isolation within the cluster, and it can be done in various ways, like having separate production and testing environments. You can have different teams using different namespaces. Configuration will need to be done if there are resources that should be available across the namespaces.
3. Storage
Non-persistent and persistent volumes
A container has a virtual file system by default, and we call it Non-persistent storage. This is because when the container is removed, the data is removed together and it does not persist.
This is why with Kubernetes we need to organise storage outside of containers, or detach it so data is not dependent on the state of the container.
You would need to consider what type of storage is required based on whether the data is structured or unstructured, requires file system or database, read only or read and write, how frequently you need to access it and if it needs to be shared across pods or multiple locations.
There are more things to consider like performance, resiliency, consistency, encryption and so on.
Examples of persistent volumes are:
- CephFS
- GlusterFS
- NFS
- vSphere Volumes
Additional features to manage - ConfigMap and Secrets
ConfigMaps store configuration settings for your code outside of the pod. This is especially important in cases like for Python and Node.js applications you need to manage application’s configurations. Remembering that a pod will need to be rebuilt when it goes through certain configuration changes, it is efficient to have configurations set outside pods, and that is why we have ConfigMaps. It helps to keep your application code separate from your configuration; which helps to create Twelve-Factor Applications. Credentials are text files, and not secure enough to store sensitive information like credentials, so Secrets are used to store these information separately.
In Kubernetes, various components are loosely coupled so that a particular container is not heavily dependent. In Kubernetes we will call it pods, but a pod is detached from services, which has its own lifecycle and assign IPs, detached from ConfigMaps, detached from persistent storage loosely coupled with the dependencies, which makes it safely able to fail and be replaced. Thus recovery is quicker and most importantly, it can be automated by the orchestrator and you can focus on the more high level operations. This is definition B that I mentioned earlier, how the loosely-coupled feature is important in a microservices architecture.
Additional features to manage - Container registry
We discussed in the Docker example in the beginning, that a container before it runs, needs to be built as an image. In Kubernetes this process is abstracted, but we still do need the registry where we securely store the images. Container registry is a place to store the images.
Security will be something that needs to be addressed, because images can contain sensitive information.
Version control is important so change can be tracked, and high availability will help to make the application able to run without being affected.
It depends on which provider, but often these are all included in a container registry.
Additional features to manage - Helm package manager
Helm is a package manager for Kubernetes. You can think of it as a similar tool like yum, apt and homebrew for Kubernetes. You can package YAML files and distribute it to public and private repositories. Any YAML files in Helm can be downloaded and applied into your Kubernetes. Public repositories are community supported, and large organisations contribute configuration files too.
My final point: why Managed Kubernetes over native Kubernetes and how much it lessens operational work
Just to summarise the point up to here, Kubernetes is an open source container orchestrator that builds on container technology, and you can design compute, networking and storage by understanding the loosely-coupled feature and utilising available tools.
Additional features are available too including container registry and Helm.
Looking at all of this, it would become clear that the operational efforts can be rather high.
There are many parts that need to be setup and managed, operation team will need to continue to learn to support these configurations, make changes as well as integrate tools like persistent storage, container registry and more. Security becomes an issue that needs to be addressed too since it is not always built in.
It is like putting together various components of a car together. This is where managed Kubernetes services come to play. Managed Kubernetes with the same metaphor, will be a completed car with less setup required and ready to go.
Managed Kubernetes is available by cloud vendors and other parties, and being a managed offering there will be costs associated, however it could still be significantly affordable compared to building the full operation foundation in-house.
For example, with IBM there is the option of IBM managed Kubernetes (IK8) which does a significant amount of automation like managing the master node for you, access to availability zones to build high availability and easy integration with storage and other solutions on the cloud.
Microservices help to build distributed systems, having high availability and meeting other requirements like compliance and latency by having workloads running in various locations, as per definition C. With public cloud, it is very easy to set up this distributed status and the Hybrid approach of IBM makes it easier to integrate with on-premise and edge locations too.
There is also the Redhat Openshift which is a powerful solution built together with Redhat after the acquisition. The following summary shows how much is automated with openshift:

Well that is not all. Have you heard of the news that Kubernetes is not supporting Docker anymore? It is not strictly unsupported since it can still be used, but if you had native Kubernetes then you would have had to manage the complexity around understanding and changing runtimes. For managed Kubernetes, this is all managed by the service provider so there will be no disruption to your work.
Considering Kubernetes is always evolving, it is good to have the peace of mind that these backend work is done for you and you will not have to set up projects and teams to redesign.
I may do a separate blog for further details, however in this blog I hope you learned that:
- There are actually many things to learn in order to consider moving to microservices architecture with containers
- You can significantly lessen the amount of operation and effort to learn details by using managed services, and that gives more time to market
Reference and good reads/watch:
Kubernetes vs. Docker: It’s Not an Either/Or Question